#아래 코드는 Kaggle Grandmaster Rob Mulla 의 모델링을 기반으로 재구성하였습니다.
대회설명: M5는 월마트에서 제공하는 계층적 판매 데이터를 사용하여, 향후 28 일 동안의 일일 판매를 예측하고 분포를 추정하는 것이 목표이다. 데이터에는 가격, 프로모션, 요일 및 특별 이벤트와 같은 설명 변수가 포함된다.
데이터셋: calendar.csv - 제품 판매 날짜에 대한 정보를 포함. sales_train_validation.csv - 제품 및 매장 별 일일 판매량 기록 데이터 포함 [d_1-d_1913] sample_submission.csv - 제출 양식. sell_prices.csv - 상점 및 날짜별로 판매 된 제품의 가격에 대한 정보를 포함. sales_train_evaluation.cs - 제품 판매 포함 [d_1-d_1941]
1 2 3 4 5 6 7 8 9 10 11 12 13
import os import pandas as pd import numpy as np import plotly_express as px import plotly.graph_objects as go from plotly.subplots import make_subplots import matplotlib.pyplot as plt import seaborn as sns import gc import warnings warnings.filterwarnings('ignore') from lightgbm import LGBMRegressor import joblib
#메모리 다운 후의 메모리 사용량 체크. sales_ad = np.round(sales.memory_usage().sum()/(1024*1024),1) calendar_ad = np.round(calendar.memory_usage().sum()/(1024*1024),1) prices_ad = np.round(prices.memory_usage().sum()/(1024*1024),1)
1 2 3 4 5 6 7 8 9 10 11 12
#다운 캐스팅이 DataFrame의 메모리 사용량에 얼마나 많은 영향을 미쳤는지 시각화.1/4 미만으로 줄일 수 있음. dic = {'DataFrame':['sales','calendar','prices'], 'Before downcasting':[sales_bd,calendar_bd,prices_bd], 'After downcasting':[sales_ad,calendar_ad,prices_ad]}
walmart 에서 제공하는 세일즈 데이터는, wrt, 즉 with respect to [ cols ] State: CA, WI, TX (3) Store: CA_1, CA_2, TX_1, WI_1, ... (10) Category: FOOD, HOBBIES, HOUSEHOLD (3) Department:FOOD_1,2,3 , HOBBIES_1,2, ... (7) item_id:: each unique id # (3,049)
1 2 3 4 5 6 7 8 9 10 11
#plotly_express 에서 제공하는 treemap 을 활용해서, 각 제품 id 를 count var로 잡고, data col 들의 관계를 directory 형태로 시각화.
group = sales.groupby(['state_id','store_id','cat_id','dept_id'],as_index=False)['item_id'].count().dropna() group['USA'] = 'United States of America' group.rename(columns={'state_id':'State','store_id':'Store','cat_id':'Category','dept_id':'Department','item_id':'Count'},inplace=True) fig = px.treemap(group, path=['USA', 'State', 'Store', 'Category', 'Department'], values='Count', color='Count', color_continuous_scale= px.colors.sequential.Sunset, title='Walmart: Distribution of items') fig.update_layout(template='seaborn') fig.show()
4. Melting the data
#4.1 Convert from wide to long format
1
머신러닝 포맷에 적합시키기 위해서는 와이드 형식의 판매 데이터 프레임을 긴 형식으로 변환이 필요하다. sales 데이터셋의 row 는 30490(== # of items), 데이터셋을 melt하게되면은 sales, calendar 30490 x 1969 = 60034810 개의 row 를 가지게 된다.
defsolution(n): pane = [[0for j in range(n)] for i in range(n)] # n * n 크기의 panel 을 만든다. dy = [0, 1, 0, -1] # 2차원 리스트 panel 에서, (dy,dx)의 움직임은, (right, down, left, up)을 의미한다. dx = [1, 0, -1, 0] ci, cj = 0, 0# 시작 포인트는 (0,0) num = 1 while in_range(ci, cj, n) and pane[ci][cj] == 0: # 1) in_range 함수를 활용, current point가 panel을 벗어나지 않음. 2) 이동하는 칸에 숫자가 채워져 있지 않음. for k in range(4): # dy, dx의 이동순서 ifnot in_range(ci, cj, n) or pane[ci][cj] != 0: break whileTrue: # 1) pannel 범위안 2) 다음칸의 숫자가 비어있을 때, 무한루프 pane[ci][cj] = num # k = 0 일 때, panel의 범위 안에서 num +=1 만큼의 숫자를 각 칸에 입력 num += 1 ni = ci + dy[k] # next point는 current point 에서 (dy,dx) 만큼의 이동값을 가져간 결과이다. nj = cj + dx[k] ifnot in_range(ni, nj, n) or pane[ni][nj] != 0: # next point 가 pannel 을 벗어났을 경우, (down, left, up, right) 순서로 이동. ci += dy[(k + 1) % 4] # (k+1) % 4 는 1 2 3 0 cj += dx[(k + 1) % 4] break ci = ni cj = nj return pane
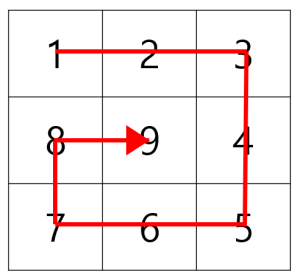
문제내용
#문제5 다음과 같이 n x n 크기의 격자에 1부터 n x n까지의 수가 하나씩 있습니다.
이때 수가 다음과 같은 순서로 배치되어있다면 이것을 n-소용돌이 수라고 부릅니다.
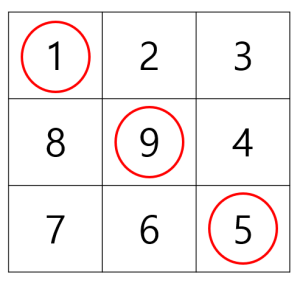
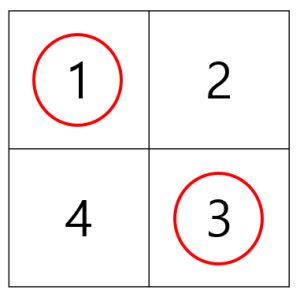
소용돌이 수에서 1행 1열부터 n 행 n 열까지 대각선상에 존재하는 수들의 합을 구해야 합니다.
위의 예에서 대각선상에 존재하는 수의 합은 15입니다. 격자의 크기 n이 주어질 때 n-소용돌이 수의 대각선상에 존재하는 수들의 합을 return 하도록 solution 함수를 완성해주세요.