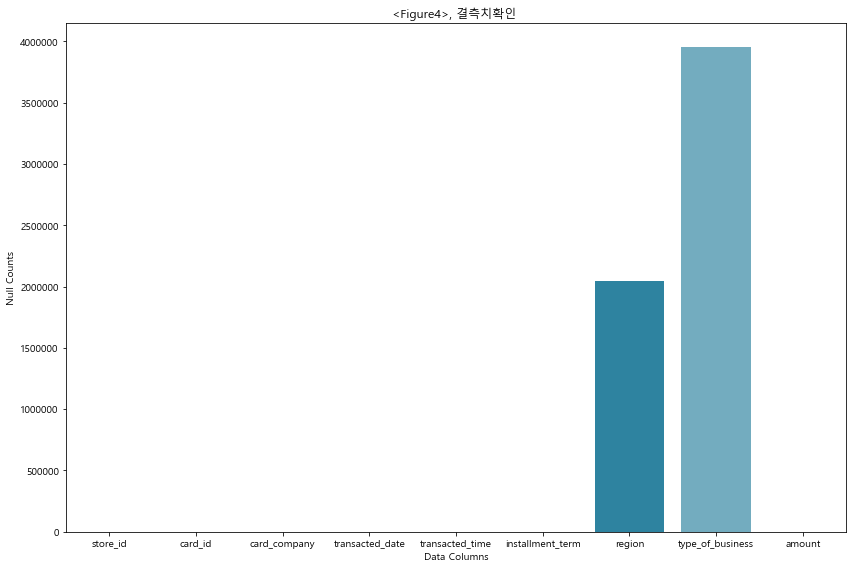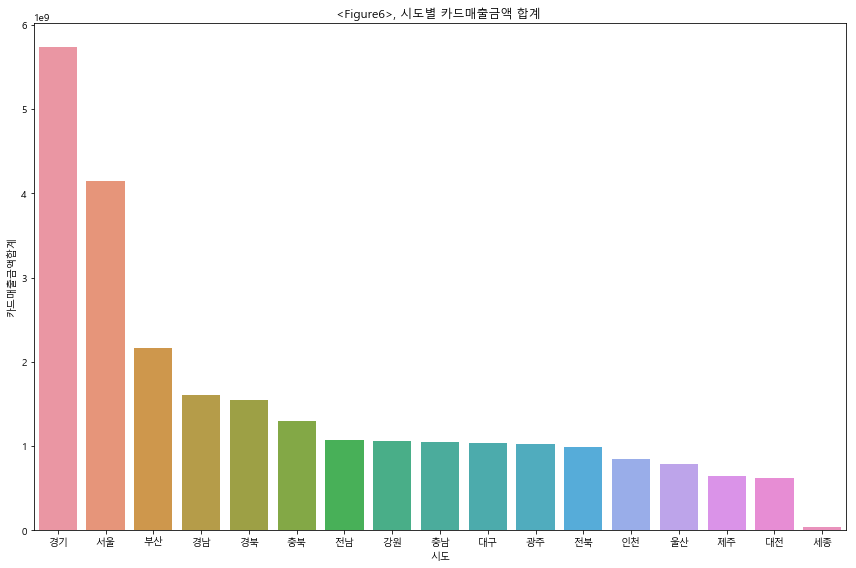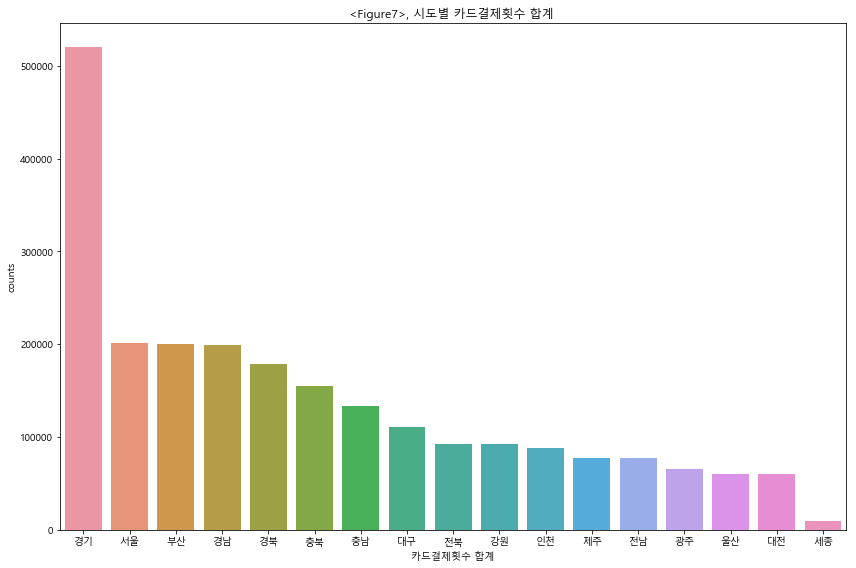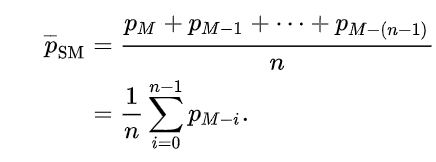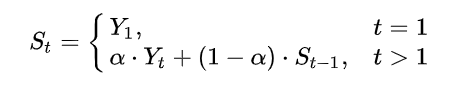개인적인 시계열 분석 포트폴리오 작성을 위하여, 아래의 DACON 대회 자료를 활용하였습니다. (현재종료 2019년 대회)
대회유형: 시계열 예측
대회목적: 핀테크 기업인 ‘FUNDA(펀다)’는 상환 기간의 매출을 예측하여 신용 점수가 낮거나 담보를 가지지 못하는 우수 상점들에 금융 기회를 제공하려 합니다. 이번 대회에서는 2년 전 부터 2019년 2월 28일까지의 카드 거래 데이터를 이용해 2019-03-01부터 2019-05-31까지의 각 상점별 3개월 총 매출을 예측하는 것입니다.
Data Description store_id : 상점의 고유 아이디 card_id : 사용한 카드의 고유 아이디 card_company : 비식별화된 카드 회사 trasacted_date : 거래 날짜 transacted_time : 거래 시간( 시:분 ) installment_term : 할부 개월 수( 포인트 사용 시 (60개월 + 실제할부개월)을 할부개월수에 기재한다. ) region : 상점의 지역 type_of_business : 상점의 업종 amount : 거래액(단위는 원이 아닙니다)
*우측 CATALOGUE 에서 Conclusion 링크를 클릭하시면 프로젝트 결과에 관한 설명 및 요약 리포트를 확인하실 수 있습니다.
프로젝트 목차
-1. Portfolio for Time-Series -2. Project Summary -3. Data_Load -4. EDA_Part_1 -5. EDA_Part_2 -6. Data Preprocessing -7. LGBM Modeling -8. Modeling_MA&EPMA&ARIMA -9. Moving Average -10. Exponential Moving Average -11. ARIMA -12. Conclusion
Data_Load
1 2 3 4 5 6 7 8 9 10 11 12 13
import numpy as np import pandas as pd from tqdm.autonotebook import tqdm import datetime from datetime import date from datetime import timedelta from lightgbm import LGBMRegressor from sklearn.preprocessing import LabelEncoder import plotly_express as px import matplotlib.pylab as plt plt.rcParams['font.family'] = 'Malgun Gothic' import seaborn as sns from statsmodels.tsa.seasonal import seasonal_decompose
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:3: TqdmExperimentalWarning: Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)
This is separate from the ipykernel package so we can avoid doing imports until
1 2
# raw data load sales = pd.read_csv('C:\Archaon\projects\Card_Sales\Dataset\copy_train.csv')
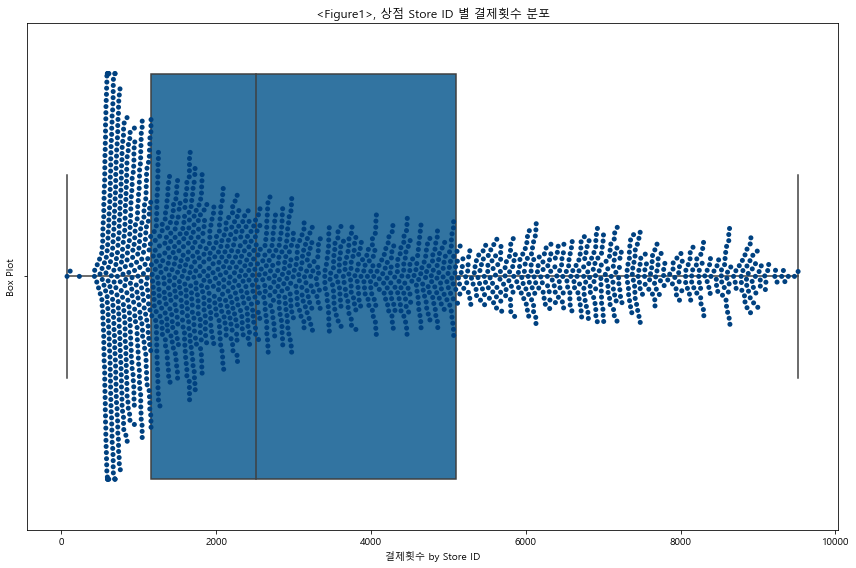
plt.figure(figsize=(12,8)) ax = sns.boxplot(x="counts", data =store_counts) ax = sns.swarmplot(x="counts", data =store_counts, palette="ocean") ax.set( Xlabel="결제횟수 by Store ID", ylabel="Box Plot") ax.set_title("<Figure1>, 상점 Store ID 별 결제횟수 분포") plt.tight_layout() plt.show()
# 1.2.2 ['card_company] len(sales) # = 6,556,613 len(sales['card_id'].unique()) # = 3,950,001 ## sales 데이터의 entry 는 card_id를 기준으로 작성되었다. ## 따라서, 1 entry = 1 card transaction 으로 이해할 수 있다. ## 하지만 데이터상의 고유 card_id 의 수는 3,950,001 개로, 전체 거래량인 6,556,613 에 비해서 40% 정도 작다. ## 그러므로 전체 거래량의 40%는 동일한 카드의 중복거래란 것을 확인할 수 있다.
## 카드 거래일자는 2016년 6월1일부터, 2019년 2월 28일까지이며, day 기준으로 1002 일이다. ## 본 대회의 경우, 1002일 간의 카드거래 데이터로, 향후 3달후의 상점별 매출액을 예상하는 대회이다. ## 따라서 거래일자는 아래와 같은 구간으로 나눠진다. ## train period : 2016.6.1 ~ 2019.2.28 (1002 days) ## test period : 2019.3.1 ~ 2019.5.31 (91 days)
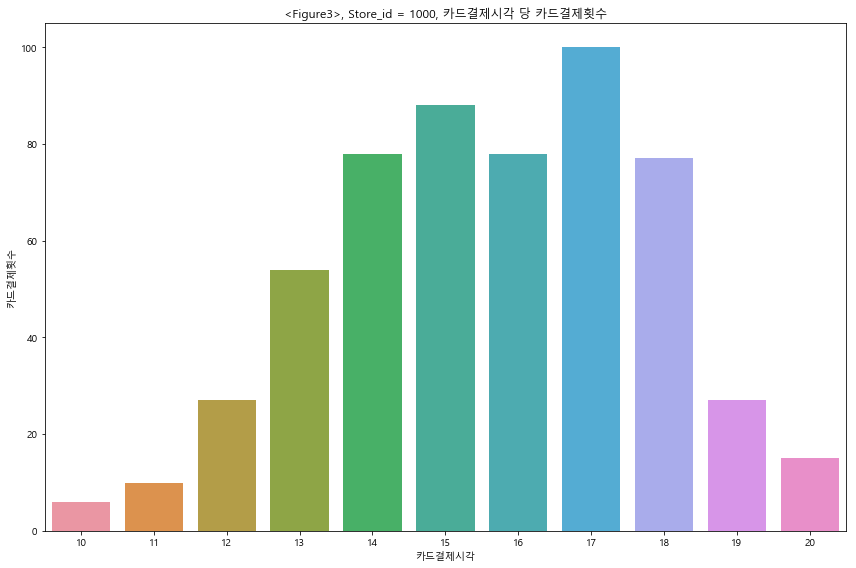
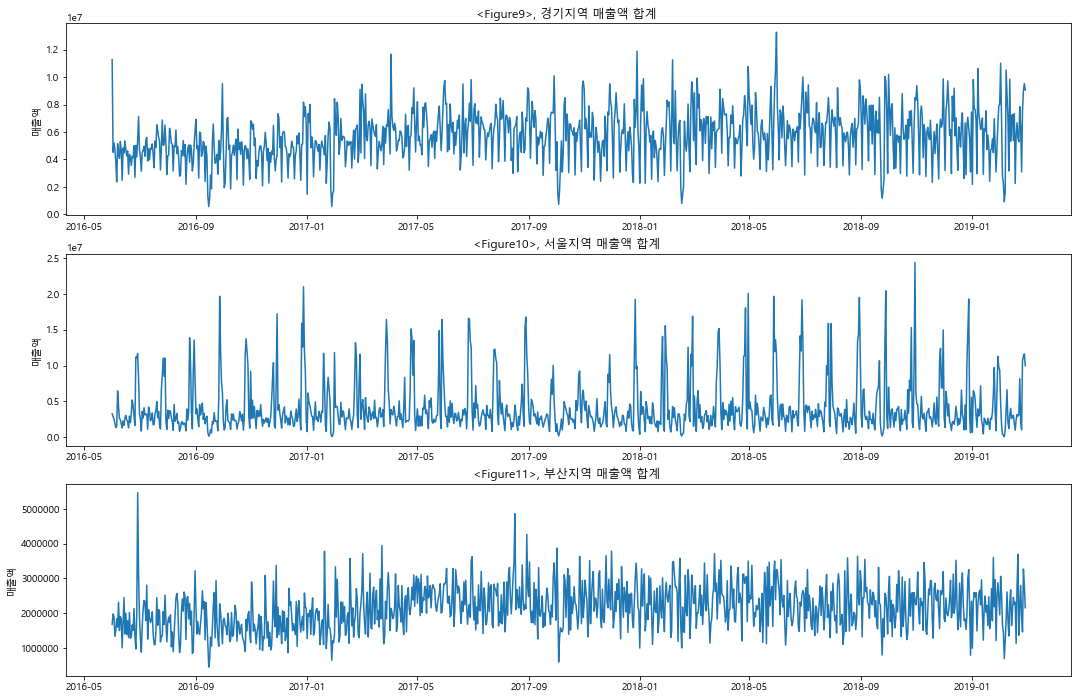
## transacted_time 과 installment_term 각각 카드거래 시각과 할부 개월수를 의미한다. ## 이러한 분포는 상점의 사업종류에 따라서 편차가 클 것으로 예상된다. ## 상점 하나(store_id == 1000)를 샘플로 골라서, 분포를 살펴보도록 하겠다. ## 선택된 상점의 경우에, type of business 가 '의복 소매업'이다. 따라서 사람들이 많이 쇼핑하는 ## 주말 오후 시간대 14 ~ 18 시 사이에, 카드결제 시간이 몰려 있는 것으로 확인된다.
store_1000 = sales[ sales['store_id'] == 1000 ] ### len(store_1000) blank = [] for i in range(0,len(store_1000)): str1 = int(store_1000['transacted_time'].iloc[i][0:2]) blank.append(str1) blank blank = pd.DataFrame(blank, columns=['Count']) time_count = pd.DataFrame(blank['Count'].value_counts()) ### plt.figure(figsize=(12,8)) ax = sns.barplot(x=time_count.index , y = "Count", data =time_count ) ax.set( Xlabel="카드결제시각", ylabel="카드결제횟수") ax.set_title("<Figure3>, Store_id = 1000, 카드결제시각 당 카드결제횟수") plt.tight_layout() plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# 1.2.6 ['region'] & ['type of business']
## region 과 type of business 의 경우에 결측치가 많다. ## region 의 경우에는 총 데이터의 31%가 결측치이며, business의 경우에 60%가 결측치이다.
## 주어진 데이터의 거래액은 카드결제 당 금액으로 입력되어있다. 하지만 예측이 필요한 3개월의 데이터는 ## 상점별 매출이므로, amount 금액 또한 store_id 를 기준으로 groupby 한 금액을 본다. ## 상점별 매출의 경우 피라미드 형태의 매출을 보여주고 있으며, 특정 상점이 이상치에 가까운 매출액을 보여주고 있다.
#region & type of business 가 있는 데이터로 그룹 나누기 sales_region = sales[['store_id','region']] sales_region_null = sales_region.isnull() region_index_list = sales_region_null[ sales_region_null['region']== 0 ].index #length 2042766 #4513847 False # Sales 데이터에서 region 값이 있는 데이터들을 찾기 sales1 = sales.iloc[ region_index_list, :] sales1.type_of_business.isnull().sum()
# 전체 데이터를 region 과 business 열에 결측치가 유무로 두 가지의 그룹으로 구분하였다. # group1(35% of all data) : region 과 business 값들에 결측치 없음 # group2(65% of all data) : region 과 business 에 결측치가 존재함 # # 보통의 경우에 위와 같이 결측치의 비중이 10~20%를 초과하면은 해당 칼럼들을 사용하지 않지만, # 해당 데이터의 경우에, region과 business 를 제외하면은 효과적으로 데이터를 구분해줄 category 변수가 전혀 존재하지 않는다. # 따라서 tree 기반 모델링을 위해서 data 를 두 그룹으로 나누고, 한쪽 그룹에는 tree 기반 모델링을 하고, 다른 한쪽 그룹에는 # non-tree 기반한 모델링을 하여서 그러한 구분이 결과값에 어떠한 영향을 끼쳤는지와 그 이유를 탐구해 볼 예정이다.
defmake_lags(data): ### Feature Engineering : lag & rolling mean blank = pd.DataFrame([]) for i in tqdm(data.store_id.unique()): store = data[ data.store_id == i] store = store.reset_index() store = store.drop(['index'],axis=1)
# lag 1,2,3,6 lags = [1,2,3,6] for lag in lags: store['amount_lag_' + str(lag)] =store.groupby( ['store_id', 'year','month','sido','business'], as_index=False )['amount'].sum().shift(lag).amount
# rolling mean 3,6 windows = [3,6] for window in windows: store['rolling_mean_' + str(window)] =store.amount.rolling(window=window).mean()
defconcat_test_set(data): ### MeanEncoding & Test Dataset
# Mean Encoding # 각각 지역평균 data['sido_avg'] = data.groupby('sido')['amount'].transform('mean') # 각각 업종평균 data['business_avg'] = data.groupby('business')['amount'].transform('mean') # 각각 지역 x 업종 평균 data['sido_n_business_avg'] = data.groupby(['sido', 'business'])['amount'].transform('mean')
# Test 구간인, 2019년 3월4월5일 치, 빈 데이터셋 만들기 for i in tqdm(data.store_id.unique()): X_test_blank = pd.DataFrame( [[0for i in range(15)] for i in range(3)], columns=['store_id', 'year', 'month', 'amount', 'sido', 'business', 'amount_lag_1', 'amount_lag_2', 'amount_lag_3', 'amount_lag_6', 'rolling_mean_3', 'rolling_mean_6', 'sido_avg', 'business_avg', 'sido_n_business_avg'] ) store = data[data.store_id == i]
X_test_blank['store_id'] = i X_test_blank['sido'] = store.sido.unique()[0] X_test_blank['business'] = store.business.unique()[0]
defdataset_month(data): # raw data 를 month 와 year 기준으로 resampling dataset =pd.DataFrame([]) for i in tqdm(data.store_id.unique()): store_zero = data[data.store_id==i] store_zero['transacted_date'] = pd.to_datetime(store_zero['transacted_date']) pd.to_datetime(store_zero['transacted_date'])
defMA_dataset(data): # 이동평균(3,5) 변수 추가 blank = pd.DataFrame([])
for i in tqdm(data.store_id.unique() ): store = data[data.store_id == i] #rolling mean 3,5 windows = [3,5] for window in windows: store['rolling_mean_' + str(window)] =store.amount.rolling(window=window).mean()
blank = pd.concat([blank,store], axis=0) blank = blank.reset_index() blank = blank.drop( ['index'], axis=1) for j in blank.store_id.unique(): X_test_blank = pd.DataFrame( [[0for i in range(6)] for i in range(3)], columns=['store_id', 'year', 'month', 'amount','rolling_mean_3','rolling_mean_5' ] ) X_test_blank.store_id = j blank = pd.concat( [blank, X_test_blank], axis=0) return blank
해당 데이터의 경우 data size 에 관한 issue 가 있었다. 처음 제공된 raw data 을 탐색하였을 때, 그 사이즈가 6,556,613 rows 로 머신러닝에 활용하기에 충분한 볼륨이 있어 보였다. 하지만 데이터는 개별 카드의 결제 건당 매출을 기준으로 작성되었고, 대회의 최종목표는 상점별 매출을 예측하는 것이었으므로 resampling 과정이 불가피 하였다. card_id 는 store_id 기준으로, day 는 month 기준으로 데이터 전처리를 하였을 때, 6,556,613 rows 에서 60,232 rows 로 데이터의 사이즈가 약 1/100 가량 축소되었다.
Data variables
raw data 에서 주어진 column 값들 중, store 를 구분 할 수 있는 categorical variable 은 ‘region’ 과 ‘type_of_business’ 두 가지가 유일하였다. 하지만 그마저도 결측치의 비율이 65%에 달하여 전체 데이터셋에 일반화하여 적용하기에 무리가 있었다. 따라서 데이터셋을 결측치 유무에 따른 두 가지의 그룹으로 나누어서 분석을 진행하였다.
Modeling
3.1 LGBM
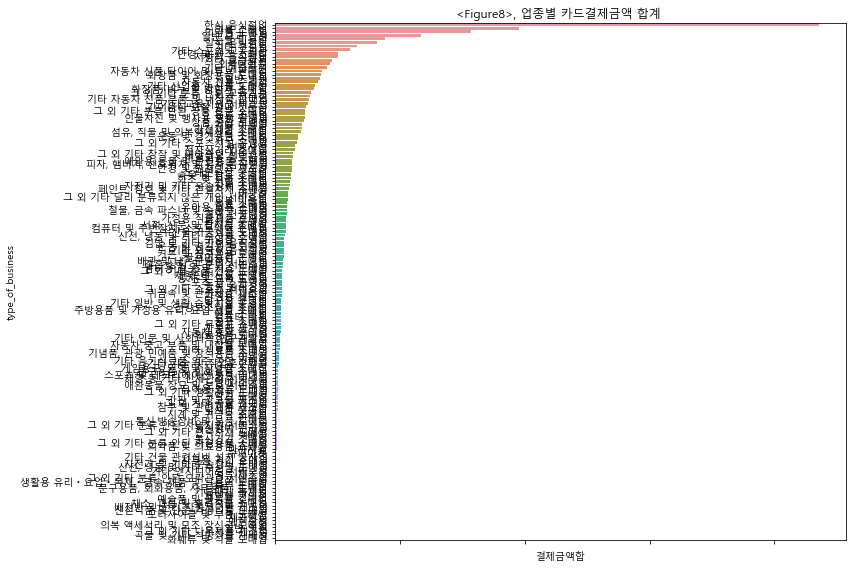
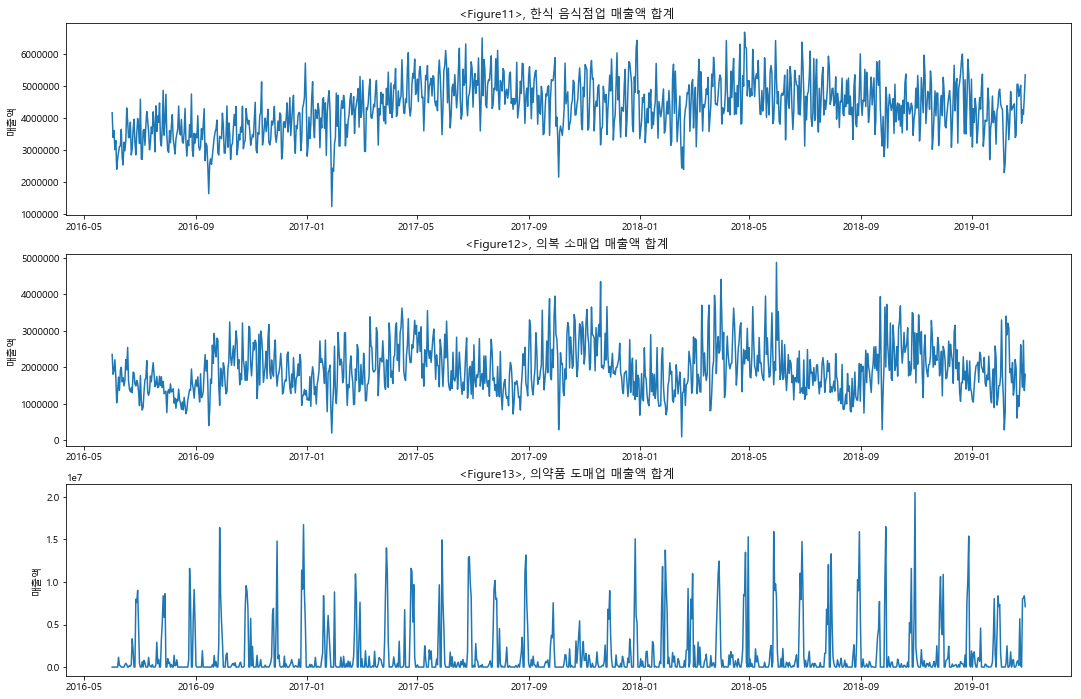
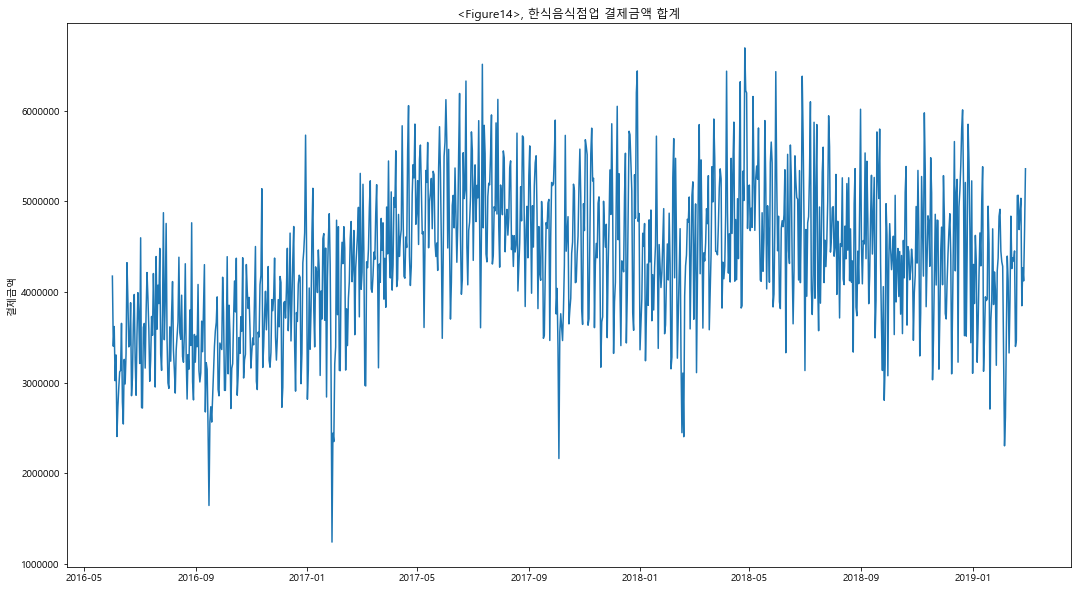
‘region’ 과 ‘type_of_business’가 존재하는 데이터셋을 group1 로 지정하고 모델링을 진행하였다. group1 의 경우에, 146개의 전체 업종 중에서 매출 top10 업종이 전체 매출에서 차지하는 비중은 50% 였으며, top1 인 한식음식점업의 경우에 전체 매출의 16%를 차지하였다. 따라서 한식음식점 및 상위 업종의 매출 trend 및 seasonality 를 중심으로 모델링 하기 위하여, Feature Engineering 과정에서 이동평균과 lag 을 적극적으로 활용하여 변수에 추가하였다. 결과적으로 LGBM 모델링의 MAE 값은 2,481,832 로 대회 Public Board 기준으로는 102등(최하위권)을 기록하였다. tree 모델을 사용하기에는 다소 부족한 데이터의 수와, categorical variable 의 부재로 인한 결과로 추측된다.
3.2 Simple Moving Average, Exponential Moving Average and ARIMA
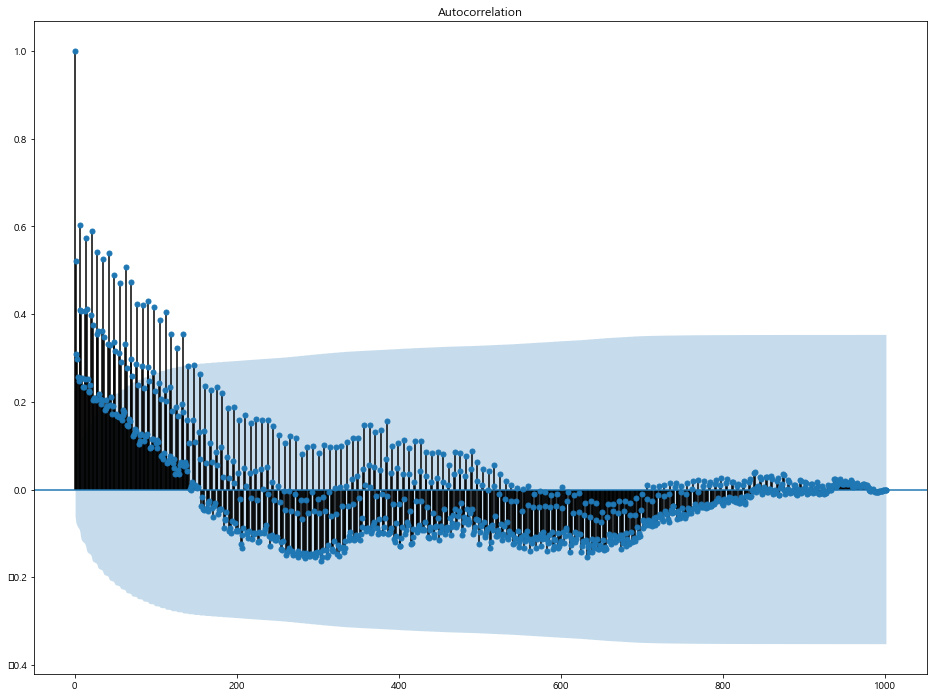
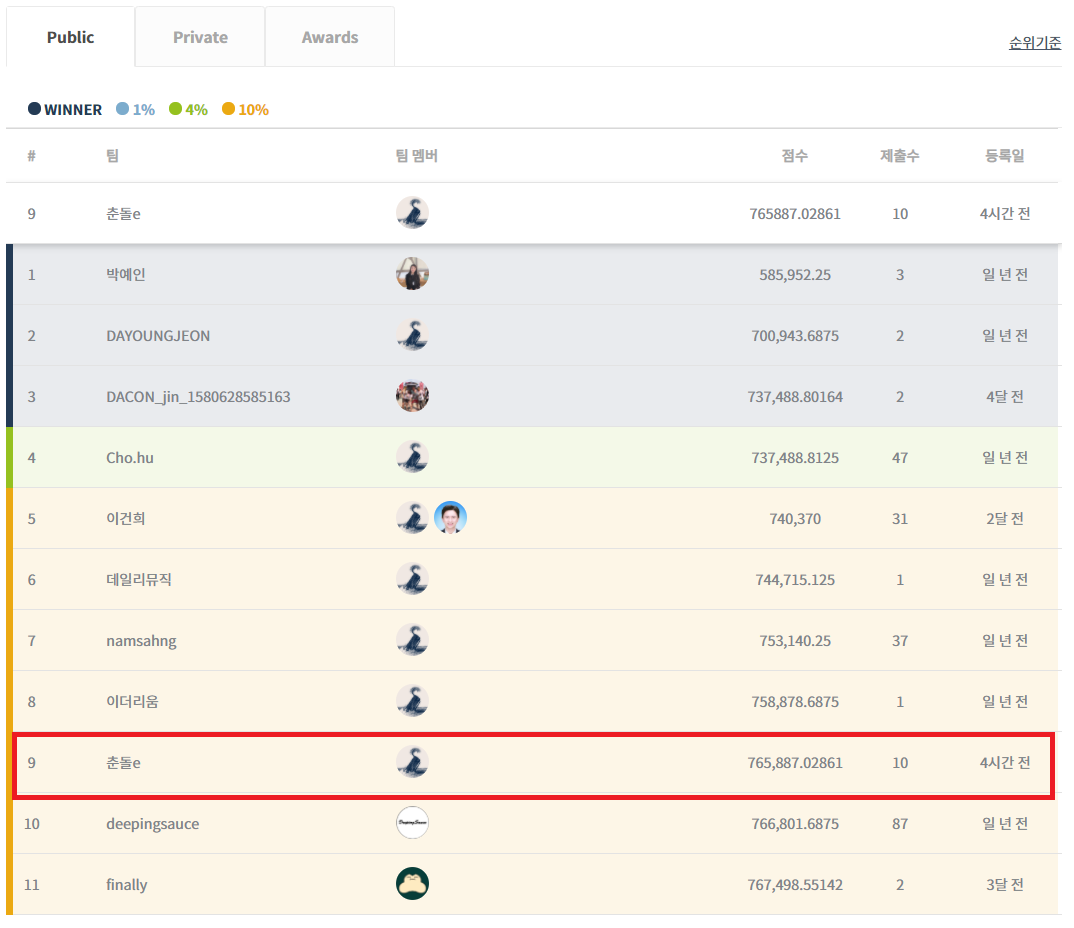
머신러닝을 활용한 모델링이 힘들기 때문에, 전통적인 방식의 시계열 분석 방법들을 시도해 보았다. 결론적으로 Exponential Moving Average(5) 에 의한 결과값이 가장 좋았다. MAE 값은 765,887 로 대회 Public Board 기준으로 9등(최상위권) 을 달성하였고, Simple Moving Average(3)가 25등, ARIMA가 50등의 성적을 보여주었다.
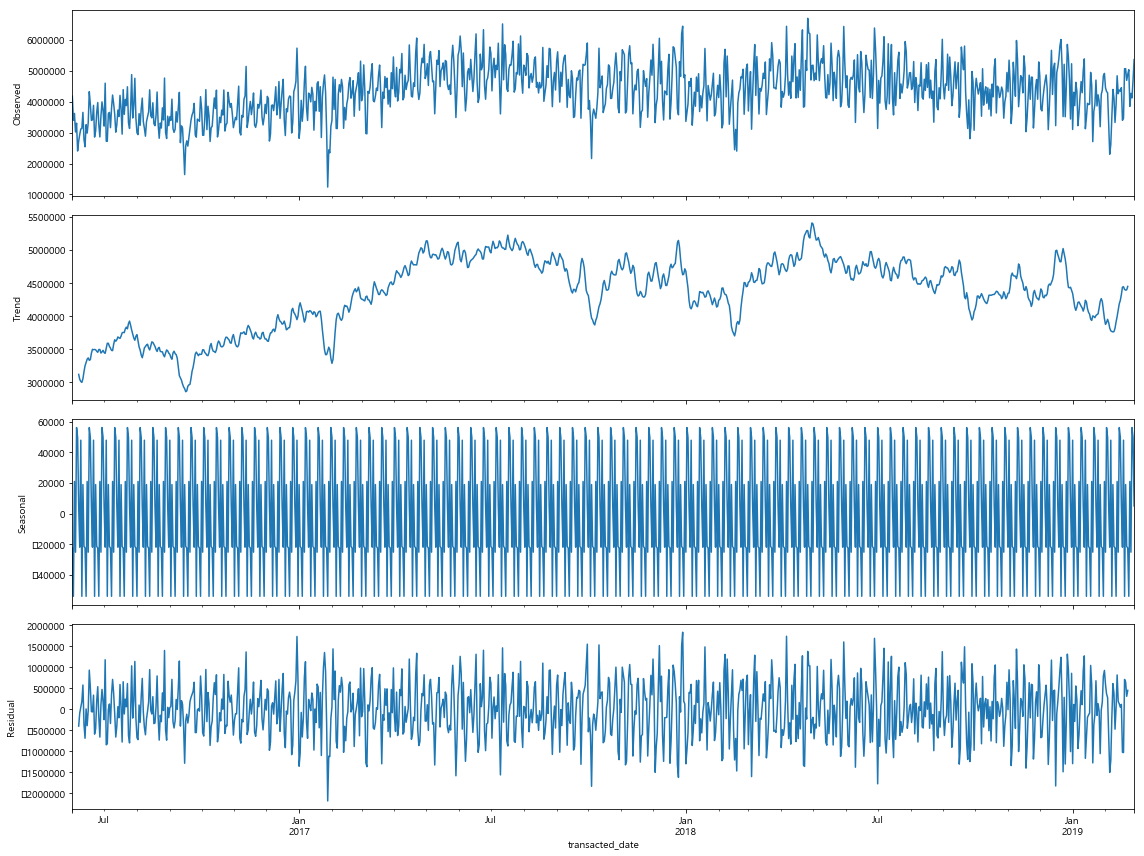
현재 데이터의 특성을 전적으로 보여주는 결과라고 생각을 한다. 각각의 모델은 아래와 같은 특징을 지닌다. Simple Moving Average (단순이동평균) 의 경우에, 각각의 시계열에 동일한 가중치를 두고 종속변수의 평균값 및 예측값을 계산한다. 따라서 계절성이 적고 추세성이 강한 데이터를 잘 예측할 확률이 높다.
Exponential MA (지수이동평균) 의 경우에는 예측시점에 가까운 데이터일수록 가중치를 강하게 가져가고, 예측시점에서 먼 데이터일수록 가중치를 낮게 준다. 따라서 단순이동평균에 비해서 최근의 데이터 변화에 민감한 예측을 하게 된다.
ARIMA 모델의 경우에는 예측값들이 가지는 관계성에 비중을 두는 모델이다. 따라서 패턴성이 강하고 시계열이 길게 주어질 수록 예측력이 높아지는 경향이 있다.
앞서 group1 에 관한 분석과 같이, 한식음식점업이 업종이 드러나지 않은 데이터 전체에서 차지하는 비중이 매우 크다고 가정할 때 한식음식점업이 가지는 데이터의 패턴은 데이터 전체에 영향을 끼칠 확률이 높다. 따라서 계절성과 추세성이 약한 요식업의 특성상, Exponential MA (지수이동평균) 모델이 현 데이터를 가장 잘 예측한 것이 아닐까 추론해 보았다.
Posted Updated Python / Cos Pro 1급5 minutes read (About 716 words)
Review: Solution 함수를 역으로 훑어오면은, price=3 일때, mn 값이 1여야 하므로, 해당 아이디어를 가지고 수식을 훑으면 수익률을 return 하는 부분인, mn - price가 아닌, price-mn 이 되어야 함을 알 수 있다.
정답코드
1 2 3 4 5 6 7 8 9 10 11
defsolution(prices): inf = 1000000001; mn = inf ans = -inf for price in prices: #price 1 , price2, mn = 1 , price3, mn = 1 if mn != inf: #mn =1001 , inf = 1001 // mn =1, inf = 1001 // mn=1, inf =1001 ans = max(ans, price - mn) # 문제 코드에서는 mn - price 로 되어있다. ans = max( -1001, 2-1)= 1 // ans = max(1, 3 - 1) = 2 mn = min(mn, price) #price 1, mn = 1 return ans
문제내용
문제10
지난 연속된 n일 동안의 주식 가격이 순서대로 들어있는 리스트가 있습니다. 이때, 다음 규칙에 따라 주식을 사고 팔았을 때의 최대 수익을 구하려 합니다.
n일 동안 주식을 단 한 번 살 수 있습니다.
n일 동안 주식을 단 한 번 팔 수 있습니다.
주식을 산 날에 바로 팔 수는 없으며, 최소 하루가 지나야 팔 수 있습니다.
적어도 한 번은 주식을 사야하며, 한 번은 팔아야 합니다.
주식을 팔 때는 반드시 이전에 주식을 샀어야 하며, 최대 수익은 양수가 아닐 수도 있습니다.
연속된 n 일 동안의 주식 가격이 순서대로 들어있는 리스트 prices가 매개변수로 주어질 때, 주식을 규칙에 맞게 한 번만 사고팔았을 때 얻을 수 있는 최대 수익을 return 하도록 solution 함수를 작성했습니다. 그러나, 코드 일부분이 잘못되어있기 때문에, 코드가 올바르게 동작하지 않습니다. 주어진 코드에서 _한 줄_만 변경해서 모든 입력에 대해 올바르게 동작하도록 수정해주세요.
매개변수 설명
연속된 n 일 동안의 주식 가격이 순서대로 들어있는 리스트 prices가 solution 함수의 매개변수로 주어집니다.
prices의 길이는 2 이상 1,000,000 이하입니다.
prices의 각 원소는 1 이상 1,000 이하의 자연수입니다.
#####return 값 설명 주식을 규칙에 맞게 한 번만 사고팔았을 때 얻을 수 있는 최대 수익을 return 해주세요.
예시
prices
return
[1,2,3]
2
[3,1]
-2
예시 설명
예시 #1 연속된 3일의 주가가 차례로 [1, 2, 3] 이며, 첫째 날에 주식을 사서 셋째 날에 팔면 수익은 2이고, 이때가 최대입니다.
예시 #2 문제에서 설명한 것처럼 무조건 한 번은 매수하고, 한 번은 매도해야 합니다. 첫째 날에 매수하여 둘째 날에 매도하는 방법밖에 없기 때문에 수익은 -2, 즉 2만큼 손실을 보게 됩니다.